
Sometimes, god knows why, we like to subject ourselves to painful endeavors. One such task I’ve recently embarked upon was to write a relatively naive HTTP server from scratch in Python. This originated as a class project for my Masters program and hence doing well was the main motivation but I learned quite a bit about efficient and secure coding practices in achieving this goal. I am by no means a software engineer (I would say ‘scripter’ more than anything else) so designing and writing a properly functioning web-server was something beyond anything else I had previously written.
Nevertheless, it had to get done. There are about one thousand different methods or mechanisms I would utilize today in achieving this goal, and perhaps I will re-write this code in the future, but as it stands the version about to be presented was my first iteration of a home-brewed web-server; it is both inefficient and poorly performing but it manages to get the job done. It currently handles GET, POST, CONNECT, DELETE and PUT as well as utilizing PHP-CGI in order to execute dynamic server-side scripting. It is written as a class which can be initialized different times on different ports and utilizes a basic configuration file to specify the available methods, listening IP, listening port, the web-content root directory, the directory for successful or failed requests, the available scripting languages and files which are protected and require authorization for access.
This particular code does not utilize any third-party modules and only uses those built into Python 3.6+ such as sys, time, threading, socket, os and subprocess. The format of the configuration file is given immediately below.

The first task undertaken by the script is to parse this configuration file and store the various components in assorted variables which will be used later on in the code as references and configuration points. The basic code for this is shown below.

The above code is a snippet from the function ‘getConfig()’ and it attempts to read the configuration file ‘config.txt’ into memory and, line by line, stores the information in the ‘config_options’ list for reference and storage into separate variables immediately after processing completes. This could be achieved through a variety of mechanisms and simply gives one example that can be used to parse through a text-file of this type. We observe that the function ‘newServer()’ is called after processing the configuration file. The contents of this function are shown below.
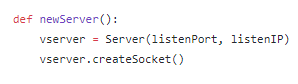
This function will initialize a new object of the Server class with the given IP and Port combinations as well as call the class function ‘createSocket’ upon completion. The next step is to begin design of the overall server class. A variety of variables are initialized for usage in the code which will not be shown here simply to save space. The ‘__init__’ function boot-strapping the system is shown below.

Here we can see that the class requires both a port and IP be passed for initialization. The previously specified root directory is used as a class variable named ‘location’ and the detected configuration settings are printed out to the console for verbose debugging purposes. We know that ‘createSocket’ is called after the init function completes so lets take a look at what that function specifically does.

The code above will attempt to create and bind a TCP/IPv4 socket to the socket address (IP:Port) combination given in the configuration file as well as calling the class function ‘portListen’ upon a successful binding. If this function fails, the ‘traceback’ module is utilized in order to print accurate debugging statements as to what exactly went wrong in the process of socket creation and binding, helping developers to understand how their code or system has failed. The ‘portListen’ function is given below.

This code snippet is hard-coded to have a maximum of five separate connections as given by ‘sock.listen’. This function will run continuously due to the infinite while loop with no breaking capabilities and every time a new connection is received from a remote IP, the socket accepts the connection and creates a new thread which is spun up using the hostname and IP passed as parameter arguments to the class function ‘processConnection’. This function contains a majority of the business logic for processing incoming connections and determining how to respond to them; ideally it should likely be broken up into multiple separate modules/functions but due to my relative inexperience with software design I have crammed far too much into far too little space. The image below demonstrates the initial portion of the function which attempts to read the incoming request and parse it into various components.

The above code is the first business logic attempting to read the incoming request. The variable ‘init_data’ is a result of reading a specified amount of the request and decoding the raw bytes into a default UTF-8 format unless otherwise specified, allowing the rest of the code to perform basic string parsing procedures. Immediately after a decode, the incomign request is run through logic which attempts to discover the specified method, URI and HTTP Version using the standard space-delimited format of typical HTTP Requests as per the RFC. If the script is unable to achieve successful execution of the code in the ‘try’ statement, the except statement will be executed. It is assumed that failure of the try statement indicates the receipt of a malformed HTTP request. This will lead to the execution of the ‘writeLog’ function with the incoming request as well as ‘0’ passed as parameter arguments as well as the formation of a response to be sent to the client utilizing HTTP Error 500 indicating a malformed request was received that does not conform to the typical standards. We see as well that the class function ‘makeHeader’ is utilized with the expected error passed as a parameter argument and upon completion it is concatenated with a response body giving a description of the error and sent to the remote client. The ‘writeLog’ function is shown below.


The above code demonstrates how, upon receipt of either a ‘0’ or ‘1’ in writeLog, either failLog or passLog will be initialized and will open and write to an existing log file containing the body of the request as well as the time the request was received. failLog and passLog are nearly identical and could easily have been condensed into one function rather than three separate ones. This was mostly due to my naivety and is something to be improved in future iterations; aggregating these three functions into one would be an easily achievable and minor change to the overall code that would require minimal effort. Don’t write bad code like me, make it good / efficient the first time around.
Lets take a brief look at the ‘makeHeader’ function in order to understand exactly what this relatively simple code routine is performing.

This function takes as a parameter argument a triple digit code which is utilized in a basic if table (which should be optimized as a switch statement in future iterations) in order to select appropriate header text for formation of an HTTP response-line with various HTTP Headers. The current date-time, server agent and ‘Connection: Close’ are utilized and placed into the response and the header is then returned to the calling function and typically sent to the remote client. Lets return back to the ‘processConnection’ function in order to figure out what happens after a successful parsing of the method, URI and HTTP version, shown below.

Even if the HTTP request contains all the expected components, sometimes we still wish to disallow the request for other reasons. As shown above, this server will only handle HTTP Version 1.1 and if the expected string is not detected in the parsed HTTP Version than the request will be denied with error 505 indicating the given HTTP Version is not supported by the server and the client will receive a response indicating that. Additionally, if the parsed method is not found within the supported methods configuration variable than the request will be denied with error 405 indicating the specified method is not allowed to make requests to this server, sending a separate response to the client. Performing this kind of server-based authorization for remote requests is important in order to filter out network requests which may be potentially dangerous such as PUT or DELETE requests that the server may not wish to handle due to their risky nature. If all of these checks are successfully passed, the business logic of processConnection then proceeds to call ‘getParams’ using the given method and clientname, with the beginning of ‘getParams’ shown below.

The intent of this function was to parse the Headers and Data which may be included in the different types of expected requests (GET, POST, PUT, DELETE, CONNECT). Since each response may have different types of headers and variable amounts of data, I decided to simply check the method as a means of filtering my business logic and for each separate method I designed a similar but slightly different method in order to check for expected headers or data existence. The first one, as shown above, was handling GET requests. GET requests should not have any data attached beyond the HTTP Headers, as per the RFC, so for each line this code routine tries to split the line on a semi-colon and if that fails then that would indicate the likely end of the HTTP Headers section. We cab observe in the GET Header parsing a basic attempt is made at detecting an authorization header and setting a flag based on this for usage with accessing protected files. The value of this header may be utilized against known good-users or values in order to provide access control to such files.
The main HTTP Headers which must be examined are those pertaining to PUT and POST requests, since these types of request must establish certain parameters in order to prevent server over-reading and other types of weaknesses in design. In particular, POST header checking ensures that both ‘Content-Type’ and ‘Content-Length’ exist in the request while PUT header checking ensures that ‘Content-Length’ exists in the request. Examples of this business logic are shown below.


It is important to track received headers in order to make sure that HTTP requests are performing up the expected RFC standards. I realize large portions of my code are repeated and could likely be condensed into better function categories and just overall made much cleaner; remember this was my first attempt at such a large project. Looking back, I recognize many different ways to improve this code-base and I am considering re-writing the entire project in order to gain more experience as well as improve the overall design and performance of this server.
Lets go back to the processConnection function and take a look at what happens with GET requests that successfully have their headers processed and make it through to the next stage of the application logic.
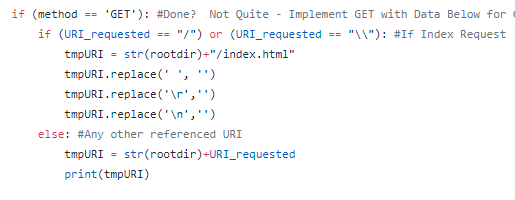
The first portion of processConnection takes over if it detects a GET request for the index page, indicated by ‘/’ or ‘\\’ existing as the only component of the detected URI. If this is the case, ‘/index.html’ is concatenated to the configured root directory and the request is passed to file-serving logic shown below.

The above code routine exists as the end of GET request processing and attempts to serve up the requested file to the remote client after reading it into memory. If the file is not found, a 404 response is created and sent to the client instead. We observe the ‘cleanUp()’ function called in either case. This function was initially intended to destroy the socket after a certain amount of connection attempts but currently does not serve any real purpose. Lets examine what happens when the client requests a dynamic script with a .php extension.

If ‘.php’ is detected in the parsed URI and PHP is determined to be an allowed script format, content-length and content-type are assumed to be 0 since this is a GET request and the parameters such as Method, IP, the query and the URI are passed to a function named ‘phpstrings’. This function sets the preliminary stage for the initiation of the Common Gateway Interface functionality and prepares the necessary strings in the correct formats as shown below, calling two other functions depending upon whether the method is detected as GET or POST.

As shown above, this function takes as input the necessary parameters to initiate a PHP-CGI request on the server and prepares them in the necessary string-variable format, proceeding to call either ‘makeget’ or ‘makepost’ depending upon which method is detected in the received request. Both of these functions are shown in raw format below in order to view the entire ‘bashcmd’ variable in each case and observe differences between GET and POST requests to PHP-CGI.

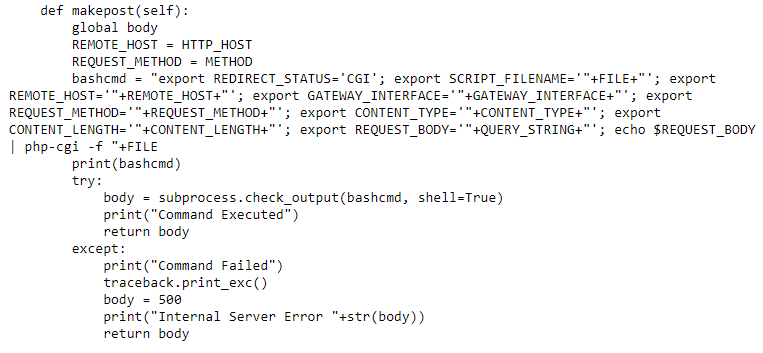
The two functions above are very similar but slightly different. Due to the requirements of PHP-CGI operations in the bash command-line, it is necessary to format the strings differently. For example, a GET PHP-CGI command does not require the echoing of the $REQUEST_BODY variable to be piped into php-cgi while a POST PHP-CGI command does. Additionally, POST commands require the usage of Content Type and Content Length while GET requests do not. In ‘makeget’, the ‘If’ statement QUERY_STRING == X indicates that it has not been overwritten and as such no query data was passed in the received request, so it is removed from the command-line string concatenation. In either case, subprocess.check_output is utilized to execute the command and the response is stored and returned via the ‘body’ variable. Referring to the images from processConnection above, this body variable is stored in the completed HTTP Response and then returned to the client, assumed to contain the successful results of the script’s execution. In the case of this project, this was dynamic HTML which consisted of a basic PHP based web-application. A very similar approach is taken to handling POST requests and will not be shown here due to this similarity.
In handling PUT, the getParameters function handles reading the attached data into ‘HTTP_Data’ and the business logic in processConnection handles writing the given data to the specified URI location. This is shown below.

This type of functionality is relatively basic and easy to achieve when compared to the handling of PHP-CGI requests. Similarly, delete is a relatively basic function to achieve in this manner and is shown below.

This code routine utilizes os.remove to delete the specified file and throws a 404 if this is not achievable. This could be improved in a number of ways, specifically detecting file access permission errors which may cause throwing the exception rather than simply throwing 404 or 500 errors in all generic cases. CONNECT is achieved in a relatively naive way. An authentication feature was imagined at first utilizing the Authorized header and that is why the check to ‘auth’ is made in the image below.

This function simply detects the resource which the client wishes to connect to, issues a new GET request to the remote resource and then returns the response to the original remote client. Rather than a full-tunnel, this essentially acts as a middle-man for network requests. This type of functionality can be dangerous due to the potential for malicious actors to use your server as a launch-spot for attacks against other parties, leaving you potentially liable for legal action and the consequences of their attacks. This is not completely up to specifications per the RFC but helps to give a basic demonstration of the functionality.
This concludes an overview of basic HTTP Server creation. Doing this type of work can help illuminate where flaws in server design will likely appear and how hard it can be to securely code large applications. There exist many types of fringe cases for request handling and, if nothing else, this has granted me a strong appreciation for developers who work on monolithic networked projects such as the Apache Server.
